History is philosophy teaching by examples. ~Thucydides
Several years ago a manager pitched his algorithmic bond trading fund to a networking group that I was a member of. As someone who had been professionally involved with creating similar systems, my questions naturally focused on aspects of methodology that my experience had shown to be critical to the development of viable strategies.
When asked how much data he used to calibrate and backtest his approach, the answer was about five years of daily data. I expressed my concern that data at that frequency over such a limited period probably weren’t enough. He gave me a somewhat pitying look and stated that bond markets were in a constant state of evolution and that going back further would be pointless because the data would not have been relevant.
Needless to say he did not receive an investment from me. The experience did, however, cause me to reflect on how my natural love of history had benefited me over the years as both an investor and investment manager, not only in understanding its importance in building models that were robust in the face of changing market conditions, but also in how it influenced my ability to assess risk and to decide what sort of risks I was prepared to take on.
The focus of this blog is quantitative finance, and I will not, therefore, attempt to undertake deep and insightful historical analyses of economic or social trends. My goals are modest. Using readily available quantitative data covering extended time periods, I will undertake a simple and straightforward analysis that lead to powerful and actionable insights into the behavior of financial markets. These are insights that are largely inaccessible to the more myopic task of calibrating a conventional financial model.
There are many examples I could have used but decided to limit myself to a single case study: market volatility over the past three decades. What does a historical perspective of that topic show us?
Characterizing Market Volatility
The variance, 

![\displaystyle{\sigma_r^2=\mathrm{E}[R^2]-\mathrm{E }[R]^2}](http://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B%5Csigma_r%5E2%3D%5Cmathrm%7BE%7D%5BR%5E2%5D-%5Cmathrm%7BE+%7D%5BR%5D%5E2%7D&bg=ffffff&fg=000&s=0 "\displaystyle{\sigma_r^2=\mathrm{E}[R^2]-\mathrm{E }[R]^2}")
If we take the maximum likelihood estimate (MLE) for the sample variance, 

^2 -\frac{\left(\sum_{t=1}^n r(t)\right)^2}{n}}")
For most return time series the term to the left of the minus sign is much larger than the term on the right. This leads to the following approximation:
^2}")
Thus, if we plot the cumulative square returns (CSR), then the slope of the CSR line is approximately the variance of those returns. If the return switches from one stable volatility regime to another, then this shift shows as an abrupt change in slope of the CSR. This is a simple but powerful exploratory data analysis (EDA) technique. With an EDA we are attempting to gain insights that give us intuition about the data. Of course, we want to make sure that our insights make sense, but at this stage we are not unduly concerned with the formalities.
Volatility of the S&P 500
To keep things as accessible as possible for this post we will use the CSR, rather than more formal regime switching techniques, to examine the volatility of the S&P 500 monthly log returns from 1985 forward, 341 observations covering about three decades. The cumulative log total returns of the S&P 500 were:
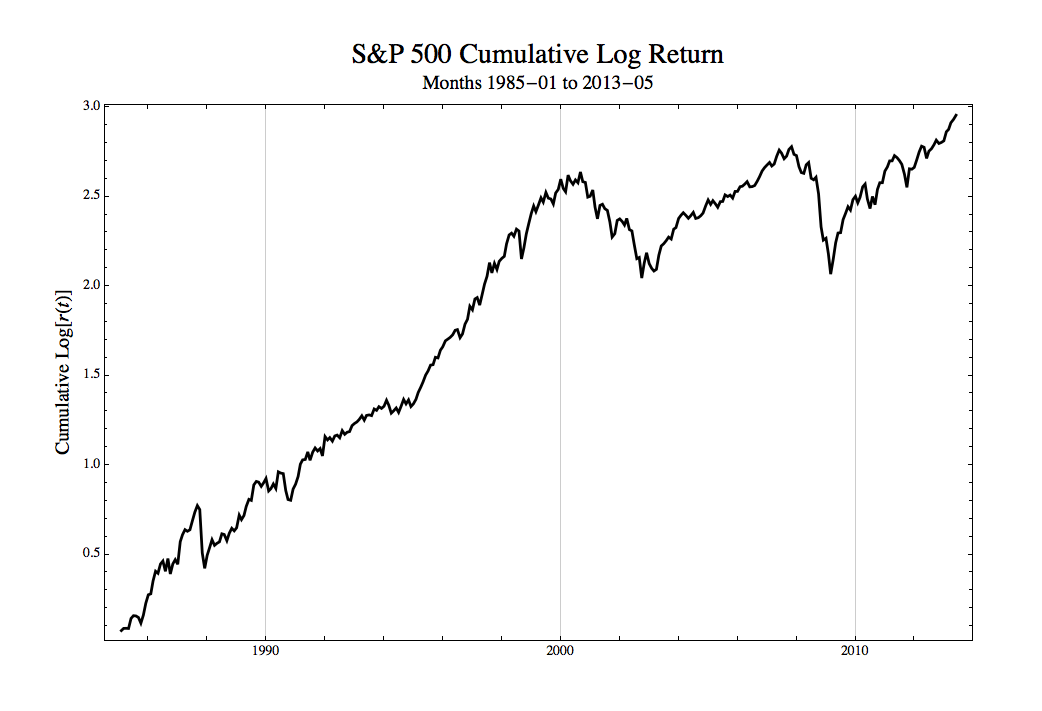
Next, we plot the CSR line to explore changes in variance over this timeframe:
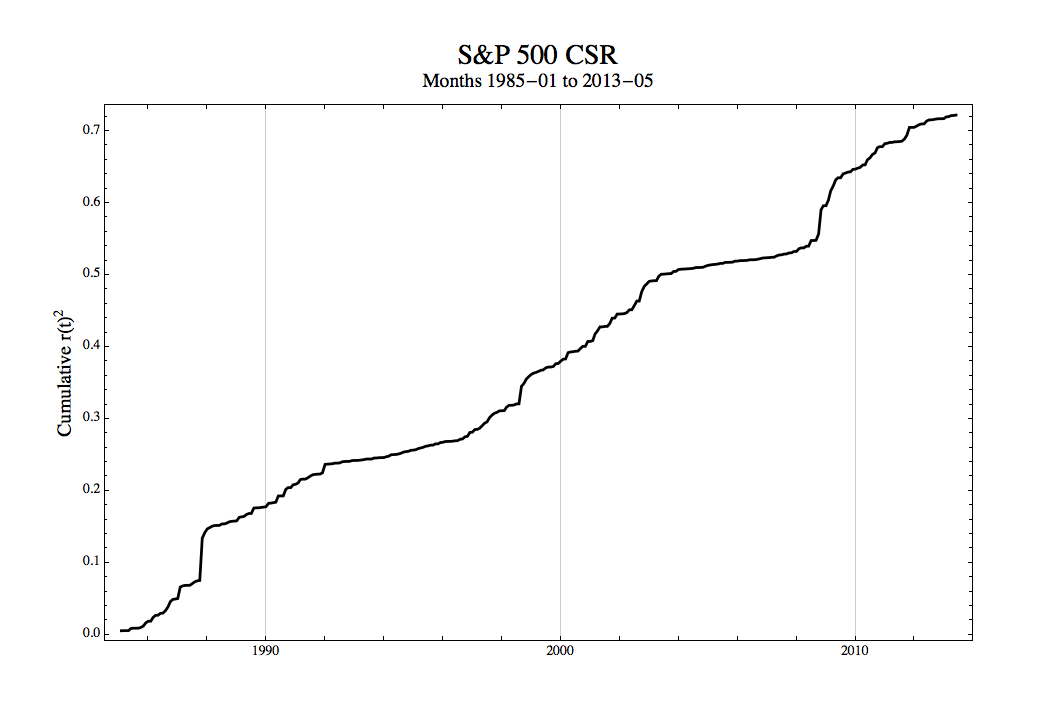
Looking at the CSR it does appear that a piecewise linear model yields a reasonably good description. There are extended periods where the slope is roughly constant, and these are separated by definite kinks showing rapid transition from one regime to another. In two cases there are abrupt, near vertical rises with the CSR immediately returning to more usual behavior. If we manually fit a series of lines (actually a simple routine using Mathematica‘s Manipulate[ ] function), then we get the plot below. The heavy black line is a channel representing the original data, and the yellow line the regimes. The dates are replaced by their integer indices to facilitate the slope estimation.
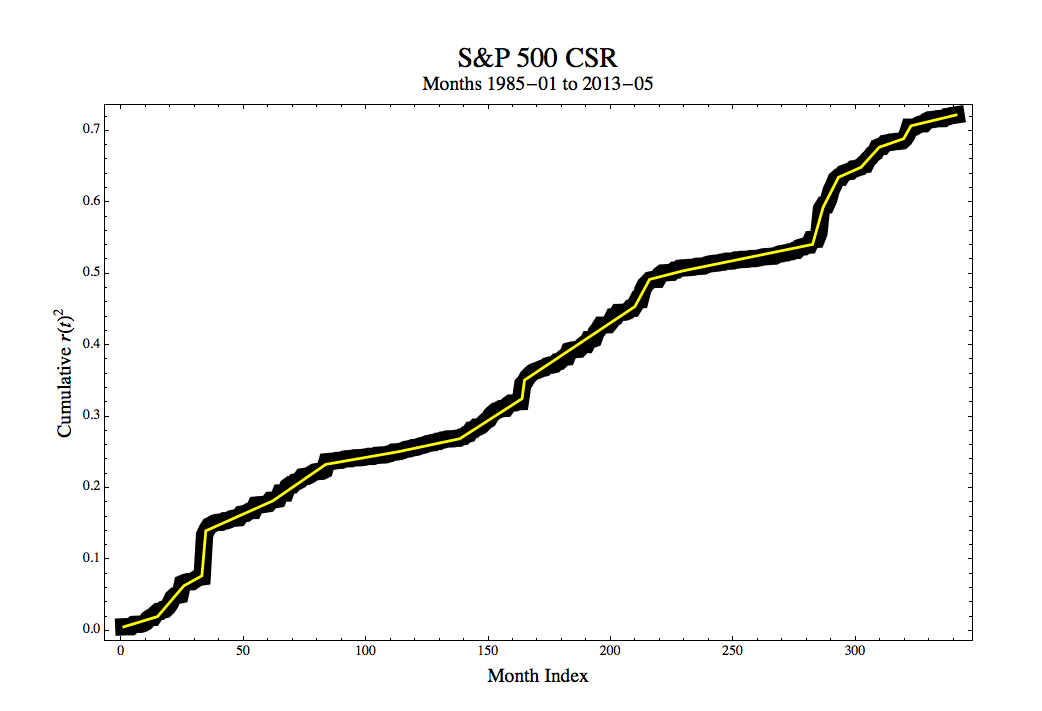
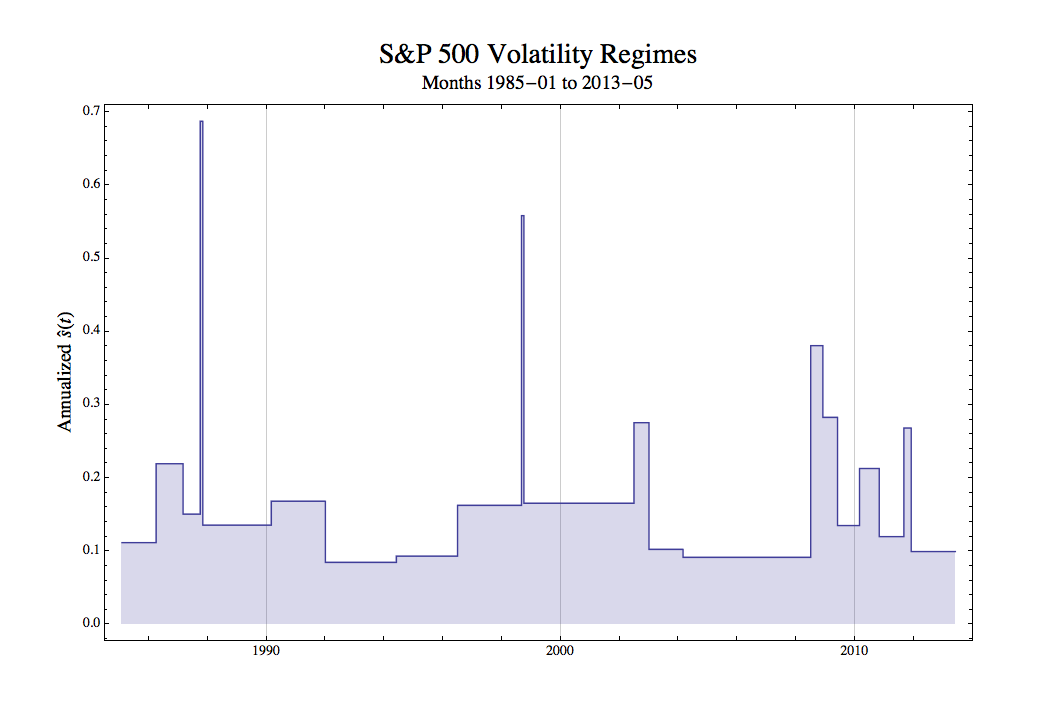
The period represent by the 

 = \sqrt{12\times\hat{s}_{\text{monthly}}(\tau_i)^2}")
More conventional methods use linear filters such as moving averages or exponential smoothing to produce dynamic estimates of volatility. GARCH and allied techniques apply ARMA-like models to the variance. While useful in certain contexts, all such approaches are low-pass filters that tend to obscure fine (i.e., high frequency) structure. Much of the apparent information they seem to reveal are often artifacts of the filter, not the data. For example, spikes or abrupt steps up and down first attenuate and then corrupt subsequent estimates until they pass out of the effective range of the filter.
Interpreting the Results
The CSR is a “quick and dirty” approach that gives a quite different view. In the above graph we see spikes occurring, not surprisingly, in October 1987 and September 1998. These events are too short in duration to give anything that is statistically significant in the normal sense, but clearly they highlight immense market moves that were far outside what might have been expected from any”normal” level of volatility.
Aside from the spikes, there were mountains, significant shifts upward that lasted a few to several months. There were also extended plains, periods lasting many years, where volatility was stable. This is a dramatically different view of volatility than we would get from a 12-month rolling standard deviation, GARCH model, or any of the other techniques that many analysts view as de rigueur.
Most importantly, rather that being obsessed with attempting to predict volatility in the short-run, we have stepped back and thought about how to gain a broad historical perspective of the various behaviors of the market over an extended period of time.
Behaviors we have called mountain and spike regimes tell us that volatility can rise and fall unexpectedly and even catastrophically over very short time frames. It is a gross understatement to say that maintaining hedges in the presence of such effects is problematic. It is also obvious that, regardless of any supposed level of significance achieved by conventional volatility models, those forecasts severely underestimate risk.
The presence of plains, periods of stability extending over many years, are by no means comforting. These plains regimes are most dangerous when their volatility is low. They lull us into a false sense of security.
In the financial markets many investment managers, traders, and analysts have spent their whole career working in such a regime. Firms are only too happy to provide consumers and businesses with the credit and investment products they demanded. Proprietary investments and trades once viewed as horribly risky seem to be wonderfully profitable opportunities with no statistically significant downside.
It all works fine as long as nothing goes wrong. Eventually, something does. The market enters a spike or mountain regime and many of the carefully validated, statistically significant models fail at once.
The Recent Low Volatility Plain
Consider recent events. From 2003 to late 2008, nearly six years, the S&P 500 was in an extremely low volatility plain regime. We had entered a “new normal”, an era of permanent prosperity. Recessions were a thing of the past as the business cycle had been forever tamed. Economic disruptions were either things of the past or could be easily managed. Buoyed by several years of successful predictions, the evidence was that our models were without material flaws; therefore, risks were well understood and tightly controlled.
Government and the Federal Reserve had led us to an economic Shangri-La. Corporate profits were secure and growing, Consumer confidence was high. Fed by easy credit and mortgage-backed securities, home ownership became accessible to a wider range of families, a social good giving more people a stake in the inexorable growth of the economy. These were safe investments on both the buy-side and the sell-side, for everyone knew that the last thing people would default on were their homes. Wall Street and Main Street prospered.
Yeah, that’s laying it on a bit thick. The whole thing was sad and ridiculous. This nonsense was sold by politicians, commentators, investment professionals, economists, and other pundits. A “new normal”? How could anyone who looked at even little history have believed that?
Conclusion
When we step back we gain perspective. Examining market volatility and other effects over the past thirty years gives us insights different from models that attempt to calibrate or forecast our volatility estimates in the short-term, although here also the understanding we gain from long-term history helps improve those efforts.
Think of it this way. When we build a house, we do not base the design on tomorrow’s weather forecast. We are more interested in the climate. We take into account rare extreme events, such as a hurricane, (spikes) by putting in storm cellars, stocking supplies, or working out evacuation routes. We worry about more conventional storms that occur frequently during the year (mountains) and make sure the structure can withstand them without difficulty. And we consider the fact that house has to be practical and comfortable in different seasons (plains) by being both warm in winter and cool in summer.
Weather prediction is immensely important; however, it is not enough. Without the historical perspective of climate studied over decades we would not be able to build a very good house. Without a historical perspective of finance and economics we cannot build effective portfolios or understand the risks of our trades.
If this post has gotten it message across, then your reaction should be that I haven’t done a very good job. Thirty years of data are insufficient. What do we find if we look at even longer time scales? Why look only at monthly data? What happens with high frequency observations? The S&P 500 is an important index, but it covers only one type of market in one country. Volatility is an important measure of uncertainty, but what other measures can be examined?
Finally, the CSR was used to keep things simple. I wanted something that would be easily accessible, and all you need for the CSR is a ruler and a pencil. There are number of powerful regime switching models that are worth your while to study, but they are often complex and are not normally covered outside of graduate programs in statistics. You may be interested in a tutorial on hidden Markov models that I developed for students in the Quantitative Finance Program in the Department of Applied Mathematics and Statistics at Stony Brook University: http://bit.ly/1aSVo4e (Mathematica notebook) or http://bit.ly/1ctr665 (PDF).
I can also recommend the work of Hyman Minski, a post-Keynesian economist, who asserted that long periods of stable ecnomic growth leads to a false sense of security and increasingly risky behavior until the economic system is so fragile that a small perturbation crashes the system. He formulated his theory mainly in terms of the characteristics of non-governmental debt: http://bit.ly/19JmWY7.
>I expressed my concern that data at that frequency over such a limited period probably weren’t enough
You were perfectly right, imho. I’d say more. There is no amount of past data which will ever “suffice” in that direction.
Why ? A a trading methodology must be self-consistent and cannot rely on a process of selection based on past data (“curve fitting”), as this would actually violate all the conceptual basis of Statistics. (I won’t go in deeper details, as this would take way too much space)
A more meaningful way to “explore” methodologies is through extensive simulation of future scenarios (eg, random tickdata based on process mixtures), that is scanning the entire sample space. But it is, in any case, more a tool and a process to refine the trading concepts, than a way to select or predict anything.
Excellent post. Much enjoyed and appreciated.
Prediction requires a more precise answer rather than a probability of occurences. This is more of dictation and interpretation of results based on non traditional mehodologies. Here is where the highly complex concept of alogorthms come into play. There has to be theory formed to create a singular result and a table to back it up. Happy Hunting!!!!!!
Pingback: clash of clans fan
There’s a typo for the annual standard deviation formula. The easiest way to fix it would be to remove the monthly standard deviation from under the square root sign.
Thank you for a careful reading. I’ve fixed the typo.